
服务热线热线:
0871-63910365
0871-63910365
 发布时间:2024-12-27
发布时间:2024-12-27 点击次数:
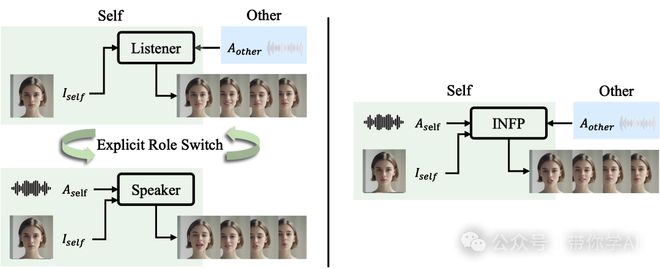
点击次数: Kaiyun官网 登录入口Kaiyun官网 登录入口想象一下,与一个具有社交智能的虚拟助手对话。它能专注倾听你的话语,并迅速提供视觉和语言上的反馈。这种无缝的交互使多轮对话能够流畅自然地进行。为了实现这一目标,字节提出了,一个全新的音频驱动双人交互头像生成框架。不像以往只关注单向交流或需要手动分配角色和显式切换角色的头像生成方法,INFP模型通过输入的双人音频动态驱动角色头像在“说话”和“倾听”状态之间切换。
INFP可以根据双人对话的音频和一张角色的照片,生成会说话、做表情、点头互动的动态视频。无论是语言还是表情、动作都非常自然,看起来像真的一样。而且这个工具体积小、速度快,非常适合用在视频会议等需要即时沟通的场景。INFP 的名字也很有趣,代表了这个方法的四大特点:互动性(Interactive)、自然(Natural)、快速(Flash)和通用性(Person-generic)。
现有的互动头像生成方法(左)采用手动角色分配和显式角色切换。 INFP(右)是一个统一框架,能够动态且自然地适应不同的对话状态。
具体来说,INFP包括两个阶段:基于动作的头像模仿阶段和音频引导的动作生成阶段。第一个阶段通过从真实对话视频中学习面部交流行为,将其投射到低维动作潜在空间中,并利用这些动作潜在编码对静态图像进行动画化。第二个阶段则通过去噪学习从输入双人音频到动作潜在编码的映射,从而在交互场景中实现音频驱动的头像生成。
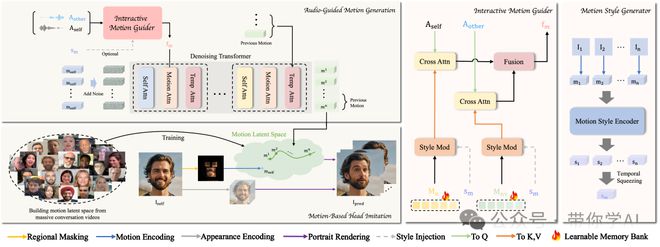
现有的双人互动数据集在规模和质量上都有一定的局限性。因此,提出了 DyConv,这是一个从互联网上收集的大规模多轮双人对话数据集。该数据集包含超过 200 小时的视频片段,捕捉了丰富的情感和表情。
使用现成的人脸检测模型,只保留那些对话中的两个人物都完全可见且面部分辨率大于 400 × 400 的帧。此外,采用了最先进的语音分离模型来分离对话中两个人的音频,分别标记为 Ap1 和 Ap2。然后,运行主动讲话者检测模型,将每个音频片段与原始视频中的相应面部匹配。

与现有方法需要显式和手动切换“倾听者”和“讲述者”角色不同,INFP方法能够动态适应不同的状态,从而实现更流畅、更自然的结果。
特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
湖南男子丧妻后娶二婚女,供3个继女读完硕博,自己3个孩子却只读了初中,亲生女儿一番话解开老父亲心结
男子非法猎捕1峰野骆驼获刑:系最濒危物种之一,全球不足1000峰,比大熊猫还稀少
热搜第一!女演员徐娇发文:劝阻男子餐厅内抽烟,取证时被抢手机,碗里被扔烟头!多方最新回应
英超悲喜1夜:曼城13场1胜 曼联5轮4负 切尔西10轮首负 利物浦3-1
威刚预告全球最小 USB4 pSSD 和首款带磁吸充电宝 pSSD 亮相 CES
354+ 个芯片平台适配小米 Vela,60+ 厂商加入全球合作伙伴计划
三星Galaxy S23系列One UI 7内测版现身服务器,或将跳过Beta测试
一加Ace 5、iQOO Neo10、荣耀GT、REDMI K80大对比

 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表
